We’ve heard people say that the only way to fix the vulnerability firehose is with automatic patching. Automating the vulnerability management process is certainly key but the complete fire-and-forget approach is fraught with problems.
In this post, we’ll explore why it’s not as simple as enabling dependabot.
Fully automated = win?
Scanning a code repository for dependencies and the associated vulnerabilities is the first step in the process. There are many tools available today that are capable of this task.
The second step is coming up with dependency versions to remedy the detected vulnerabilities. This step also involves creating a ticket or even patching the dependency file and auto-generating a pull request.
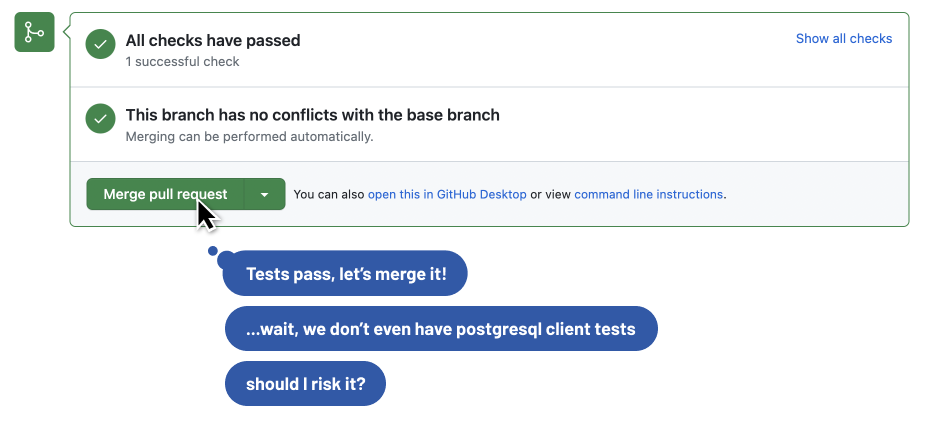
From this point on, it may seem that the only thing left to do is to click the “Merge” button.
Unit testing doesn’t fully exercise third party dependencies
Before merging any code, we need to make sure that the change does not introduce any regressions. This is typically done with tests, hopefully automated tests.
More often than not, these automated checks are unit tests. However unit tests are designed to exercise a section of code authored by an end user, like a developer at a bank.
What they’re not designed to do is to exercise third-party dependencies. For example, a unit test will typically mock the database under the assumption that it works as expected. But an upgrade to the postgresql client library may violate this assumption.
When upgrading dependecies, automation aids in the mechanical actions of bumping versions, but doesn’t relieve any mental load or reduce much risk.
Integration tests are better but are harder to automate in CI
To ensure that the application works end-to-end, integration tests are a better fit. However they are (almost by definition) harder to automate in a CI environment.
As such, most teams perform integration testing as a step in the deployment process. For companies that utilize continuous deployment, this is part of running on staging and canary environments in the deployment pipeline.
If an issue is caught at this step, that’s absolutely a win, but now your pipeline may be blocked while that code is backed out. If you do release trains with multiple changes included, all of those must be backed out and separated.
My experience fixing security issues at Lyft
I have seen this firsthand while working as a software engineer at Lyft. The infrastructure team had tools to issue pull requests against the application repositories and left it to the project owners to merge and deploy those upgrades.
As part of CI/CD discipline, we tried to deploy each merged PR separately from others. This allowed us to isolate any regressions and quickly revert problematic PRs.
While the deployment was easy to trigger, it required being vigilant as it progressed through the pipeline. For each successive environment, we allowed the new artifact to “bake” for a specified amount of time.
As it did so, we carefully monitored Grafana for increased errors rates and response times. Therefore merging and deploying a trivial dependency upgrade was a serious distraction from pressing tasks at hand.
The true cost: constant distraction
This is the true cost of vulnerability patching: the constant distraction from working on the application itself.
Here at EdgeBit, we want to reduce this distraction by giving developers and security engineers more context into which vulnerabilities need to be fixed today and which ones can be deprioritized.
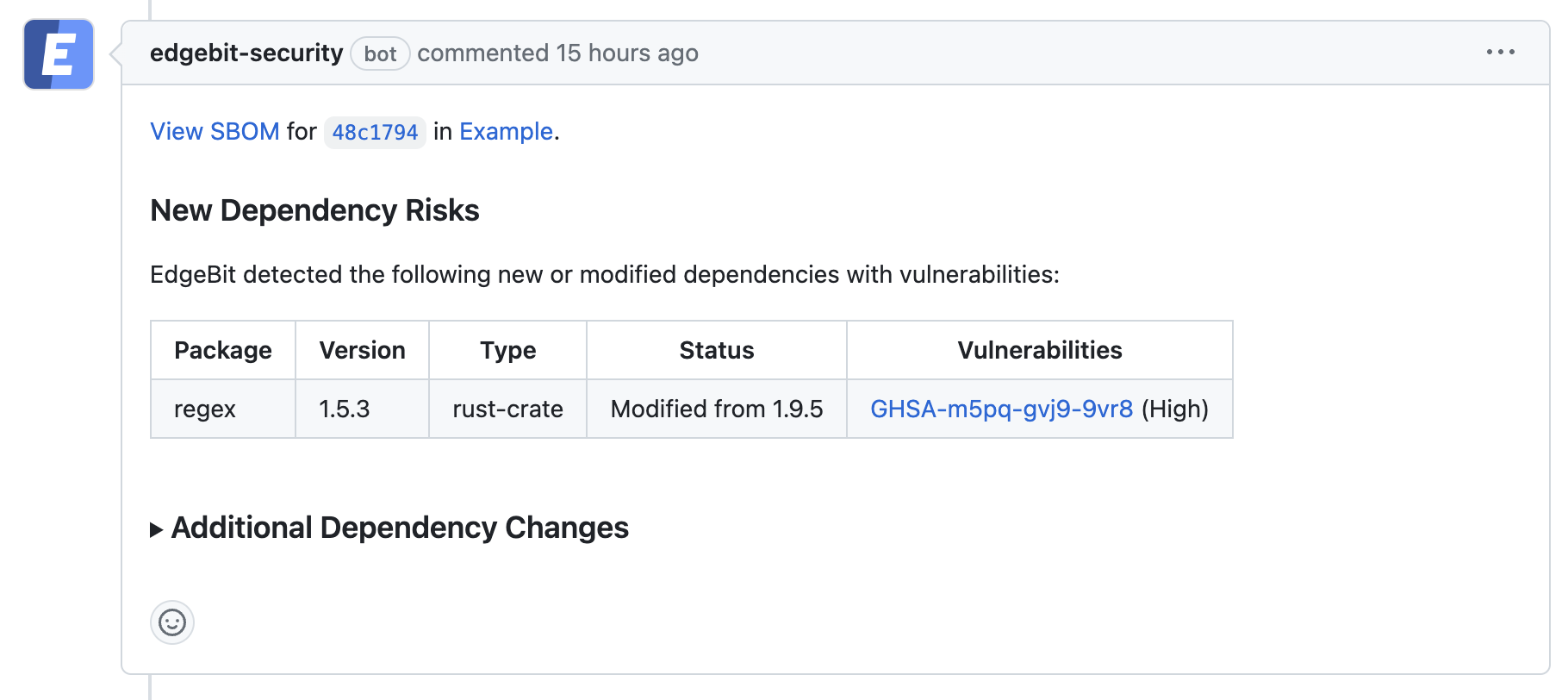
By understanding what runs in production and then tying it back to the build step, we can focus the engineers’ attention on only those dependencies that are in the exploitability path.
Try out EdgeBit
EdgeBit secures your supply chain and simplifies your vulnerability management by focusing on code that’s actually running. Free your engineers from useless investigation and focus on real threats.