A comprehensive security posture is built on successful vulnerability management. The firehose of security issues is coming whether you like it or not. Successful programs must cut through the noise. The teams at Lyft (blog) and Elastic (blog) have both recently shared details about how they prioritize and remediate CVEs.
They both share a common trait that is so critical we built EdgeBit around it — context about how your software is executing right now is the most effective filter to ensure engineering teams focus on real threats.
To quote Elastic:
To fully optimize our vulnerability management solution, it is essential to enrich vulnerability and asset data. Context is crucial!
Engineer happiness is essential for success and there should not be any animosity building over useless investigation or noise in their workflow.
Containers are an extension of the host
With the proliferation of containers, management of OS packages has moved from a central infrastructure team to individual engineering teams who are free to choose base images and make modifications as needed.
Lyft’s program only covers OS packages, but with layered container base images, this narrow scope is still a complicated problem. They curate a set of base images, but updates in those need to trickle down to the final container images.
Because each team at Lyft is responsible for their own deployments, tracking which containers are running in production requires a live inventory, not just looking at a Dockerfile in git.
EdgeBit cofounder and previous Lyft engineer Eugene Yakubovich wrote about how shepherding these deployments is a large mental load even if the pull requests to upgrade dependencies are automated.
Effective Prioritization
How do you eliminate the firehose of security issues for your engineers?
Be extremely selective of what lands on their radar:
- Is the vulnerable code running in production now?
- This automatically bumps up the priority vs other issues.
- Does this dependency or library typically execute? Is it an active dependency?
- If upgrading to a new version will introduce a new vulnerability, that’s a problem — you need to know ASAP, eg. in the pull request.
- Is there a fix available for the issue?
- If a new version resolves the issue, that is great. Let’s start testing out those changes.
Lyft’s security team states their goal as such:
Any guidance we (as the security team) provide to a service team must be actionable. We must only ask a service team to fix an issue if we are confident that it is fixable.
Elastic does weekly notifications to teams and is investigating more advanced prioritization:
In the near future, we plan to use this workflow to provide prioritization using a host risk score (calculated from EPSS scoring and asset context)
Exploit Prediction Scoring System (EPSS) is an effort to crowdsource exploitation data from honeypots, intrusion detection systems and similar tools to augment CVE data. CISA’s Known Exploited Vulnerability catalog is a similar but smaller dataset.
We think this is a great effort but understanding your situation on your servers can never be beat. This is why connecting the loop from live systems back to the build pipeline is such a powerful focusing factor.
Remediating false positives at the wrong time
The team at Kenna Security/Cisco did a study of vulnerability prioritization purely based on CVSS score and found that using a score of 7 is the most efficient, if you had to pick a number.
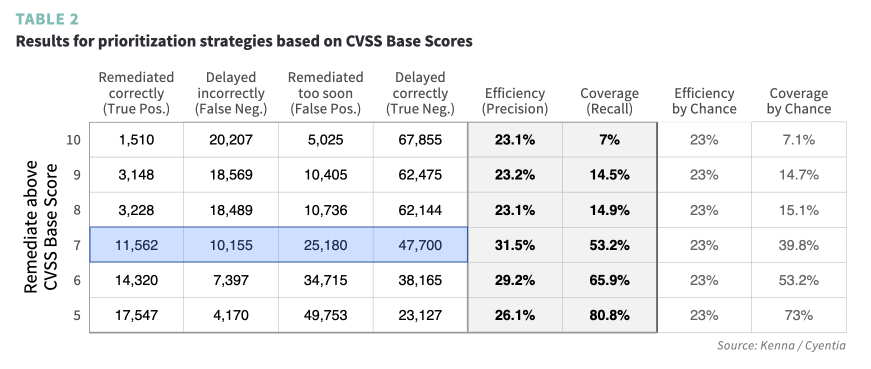
However, you’re still making a decision without context, which leads to 25,000 vulnerabilities which were remediated too soon.
Sysdig’s 2023 Security Report reached the same conclusion:
In fact, 85% of critical and high vulnerabilities have a fix available, but are not in use at runtime where they’d be exploitable.
Instead of guess work, give your engineers direct insight into what’s running in production now, what’s moving through the build pipeline, and what’s been fixed but not deployed yet.
Life of a Developer Using EdgeBit
Now that we’ve prioritized the issues to fix first, let’s get to it!
Here is the EdgeBit bot confirming that our Pull Request introduces a new issue when downgrading a dependency:
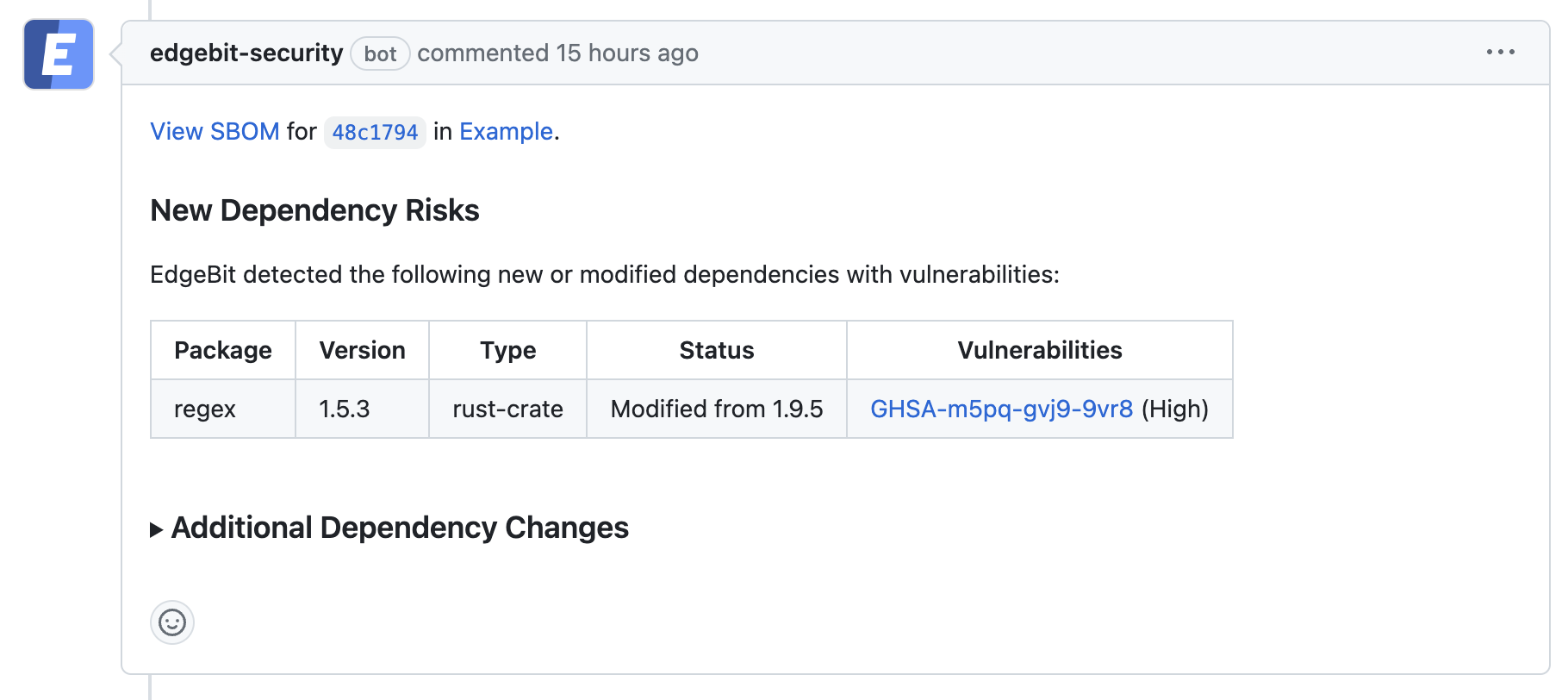
Common situations that EdgeBit helps with:
- fixing a known vulnerability in an existing dependency
- alerting to security issues with newly added dependencies
- confirming a lack of vulnerability when upgrading a dependency
- deprioritization of vulnerabilities for dormant dependencies
All of this without having to leave the build pipeline — EdgeBit brings all of the context from the production fleet to each developer.
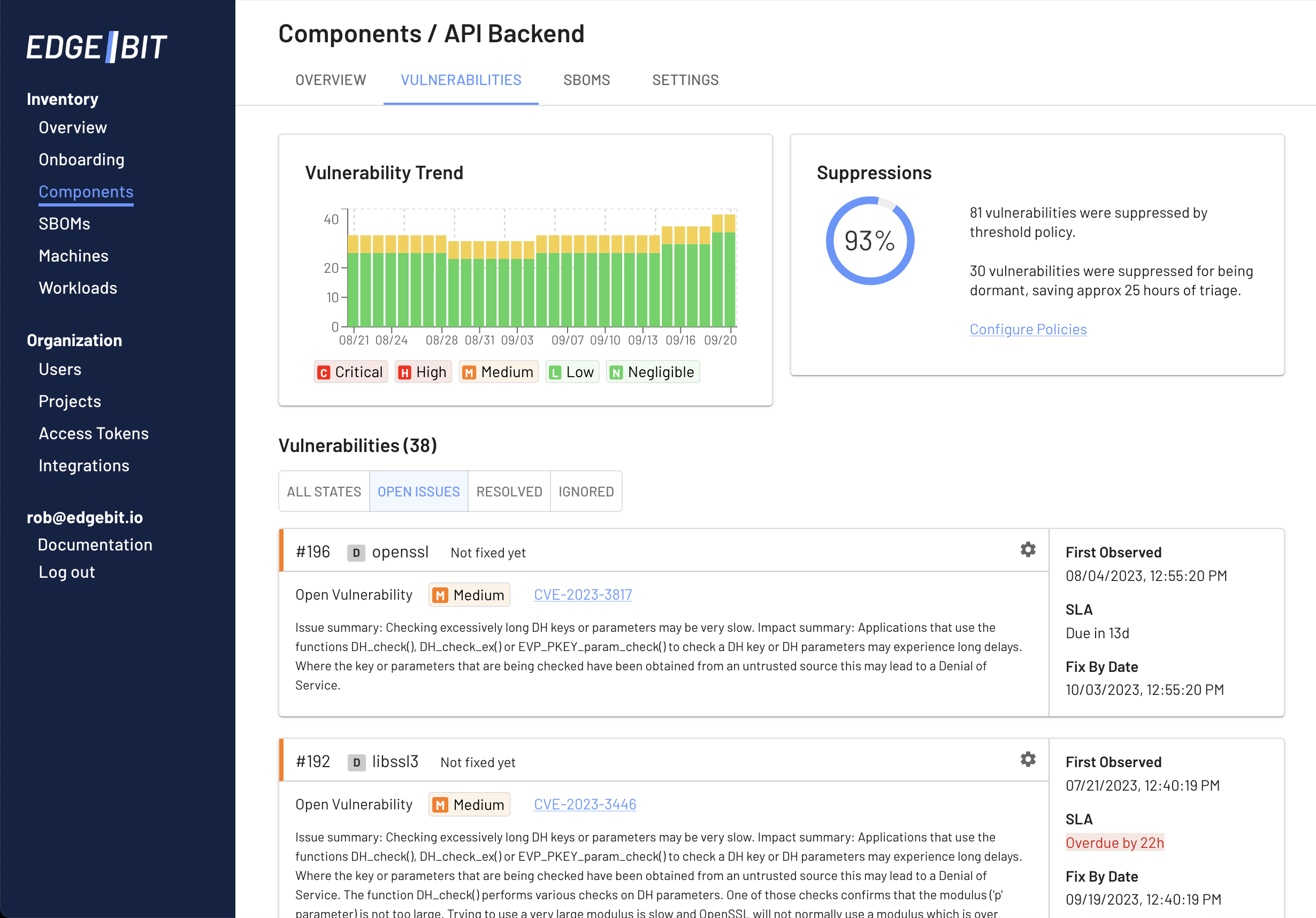
To get a sense of vulnerabilties trending over time, you can jump over to the EdgeBit console:
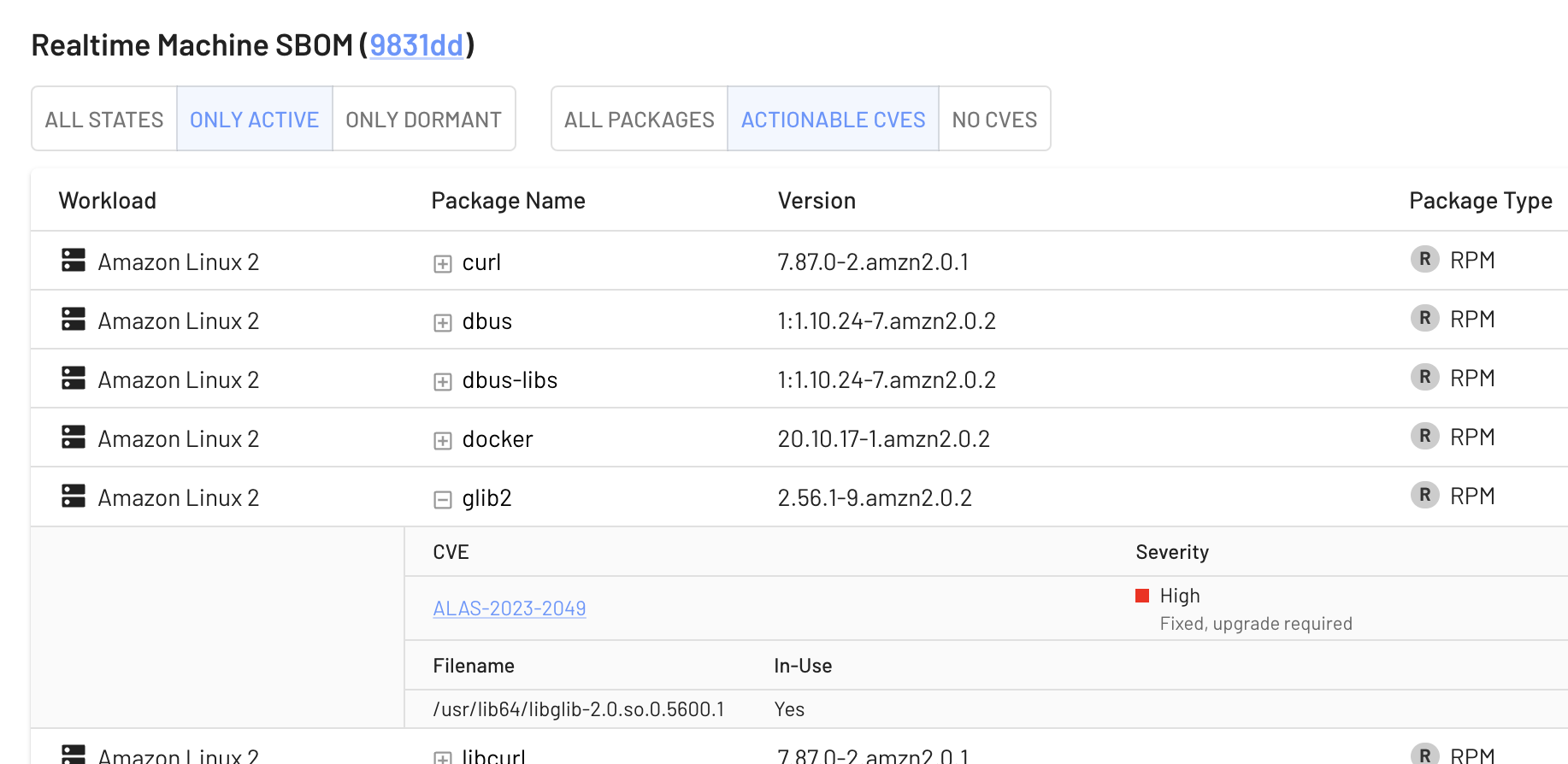
If you want to dig into a specific machine or workload to see what’s in-use right now, it’s extremely easy:
Try out EdgeBit
EdgeBit secures your supply chain and simplifies your vulnerability management by focusing on code that’s actually running. Free your engineers from useless investigation and focus on real threats.